今年(2024年)から画面外字幕表示用のスクリプトを新しくしました。この時、スタイルも若干変更したため、2023年以前の動画字幕にも影響が出てしまいました。
放置しておいては落ち着かないので、過去記事も字幕スクリプト名を置き換え、スクリプトを一本化することにしました。以下、行った作業のメモです。
continue…▶今年(2024年)から画面外字幕表示用のスクリプトを新しくしました。この時、スタイルも若干変更したため、2023年以前の動画字幕にも影響が出てしまいました。
放置しておいては落ち着かないので、過去記事も字幕スクリプト名を置き換え、スクリプトを一本化することにしました。以下、行った作業のメモです。
continue…▶しばらく遠ざかっていた長文要約の自動化を、ちゃんとやりたくなりました。
字幕起し翻訳の対訳表の下に、各字幕を連結してじっくり読めるようにした文章をつけていますが、これの要約があれば記事を読む人の助けになるだろうと思いました。
各記事のハイライト部分は筆者が判断してセンテンスを選んでいましたが、ここを機械の助けを借りて、より客観的なものにしようと思います。
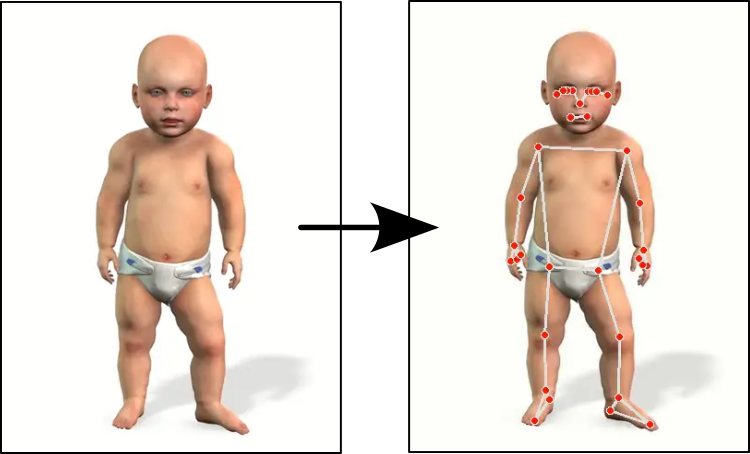
continue…▶1月21日に顔メッシュの記事を載せてからほぼ2ヶ月、どうやら「画像や動画の座標データからBlenderオブジェクトを作成する」という目標を達成したようなので、仕上げの記事をまとめます。
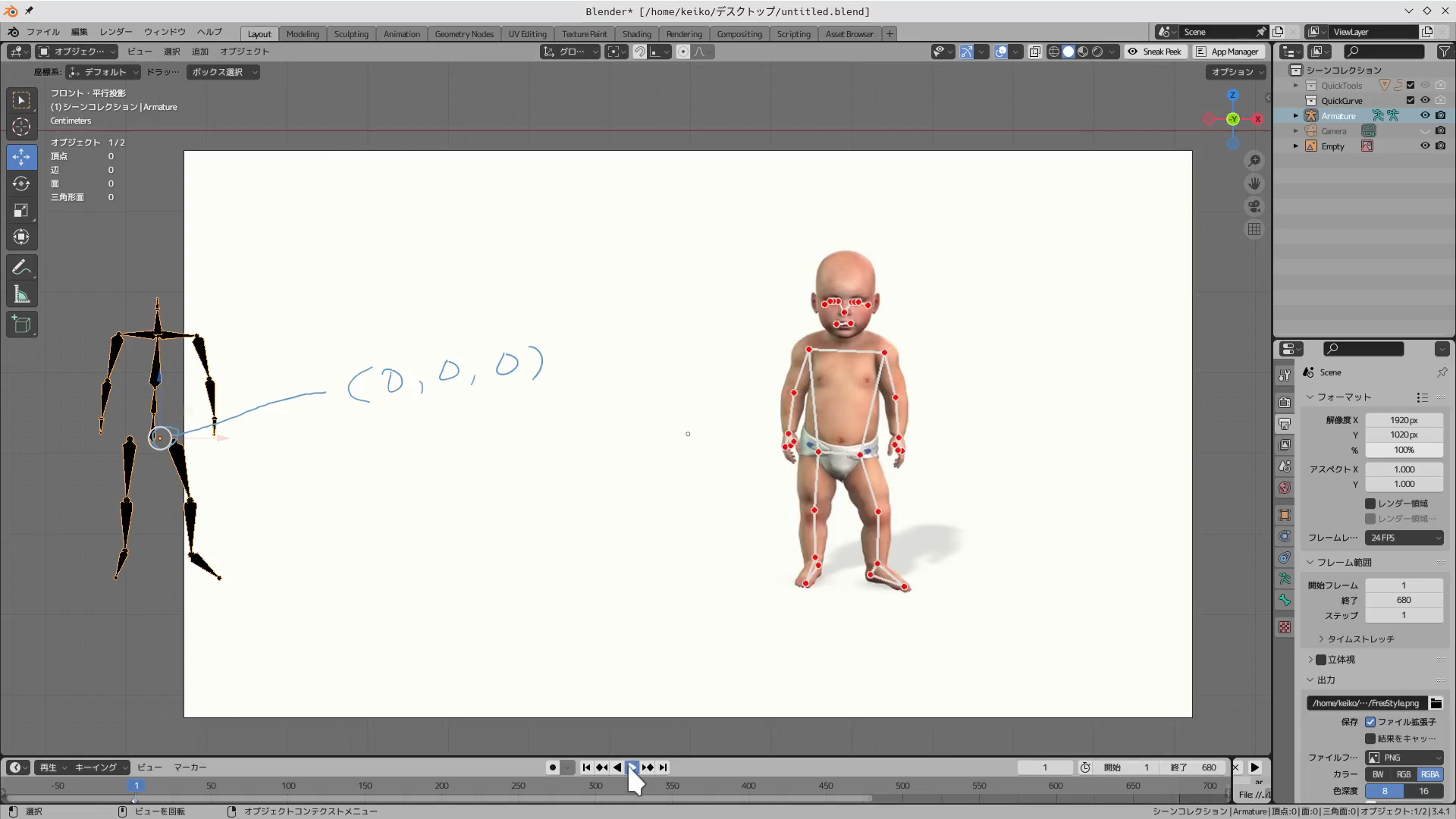
continue…▶動画のランドマークを元にしてBlenderのアーマチュアが同じ動きをするか試しています。
今のところ、位置はなんとかなりましたが、個々のボーンの角度がまるでダメダメです。ただ、プログラムのどこを修正すればいいかまでは分かりましたので、途中経過をお知らせしますね。
※このページに掲載したコードは、キーフレーム設定の部分を最終版でかなり修正したので、あまり参考になりません…。
動画の文字起こしをするための自分用ツール、mojiokosher.py。
当初はGtkウィンドウの中に動画再生とテキストエディタのウィジェットを持たせるつもりでしたが、テキスト編集は既成のエディタでよさそうなので、ビデオを再生することにフォーカスします。
continue…▶