GTKのチュートリアルを一通り読み終わったので、アプリ作りに取り掛かれるはず…。なのだけど、実は翻訳文を読んでも内容はよくわからなかった。\(^o^)/ 自分用に実際にコードを書いたり動かしたりの作業をまだ始めてないので、クラスやメソッドやプロパティがちんぷんかんぷんなのは当然かもです。
まず現状を書き出して、それから最終どういうアプリが欲しいのかイメージしてみましょう。そして、少しずつでいいからプログラミングが上達するように願いを込めて、取り掛かりましょう。
なぜ文字起こし?
筆者は2019年の夏、会社勤めを辞めました。辞めてしばらくは「さてこれからどうしよう?」と、この先打ち込めるものが何なのかわからず、迷いの日々を送っていました。
「3Dソフトを漫画の下描きに利用しよう」とか「3Dプリンタで小物を作ろう」とか、それなりに楽しい試行錯誤をのんびり続けているうちに、世の中は武漢ウィルスのせいでものすごい勢いで様変わりしてしまいました。
ぼやぼやするとフェイクニュースに流されそうな情報氾濫の中で、「正しいことをしっかり覚えて自分の考えを持たねば!」と危機感をつのらせました。何かしなくてはいけない気持ちが日々強くなっていきました。
そこで差し当たって試みたのが、優れた言説が述べられている動画の文字起こしです。話されている音声からテキストを作成する作業はいろんな感覚を動員するので、受け身で情報に接するのに比べて、とてもよく頭に入ります。書かれたものが出来上がれば、それを要約したり図解したりなど、知識として定着させる手段がたくさんあります。英語に翻訳するのも今はオンライン翻訳ツールのおかげで短時間でできるようになっています。文字起こしをすることで、様々な方法で知的能力が鍛えられるだろうという期待が持てました。
昔、アルバイトで少し文字起こしの仕事をしたことがあるので、今度は自分のためにそのスキルを活かそうと思いました。
今どういう方法でやっているか
フリーのソフトをいくつか組み合わせて、以下の手順で文字起こし作業をやっています。
- 文字起こしをしたい動画を用意する
- Audacityで .wav ファイルを作る(16000Hz, モノラル)
- Audacityのラベル機能を使ってセグメンテーション
- 作業用の小分け動画と小分け音声ファイルを作る
- 音声が日本語なら Julius 、英語なら DeepSpeech 、音声認識エンジンを使ってテキストを出力
- 小分け動画を再生しながらテキストを修正する
それぞれの段階についてもうちょっと詳しく書きますね。
1. 動画ファイルの入手
自分用に文字起こしをしようと思い立った当初は、YouTubeから動画を選んでダウンロードすればいいと思っていました。が、なんと! YouTubeの利用規約に「ダウンロード禁止」とあります。ダウンロードというのは、いろんなツールがあって作業的には可能なんだけど、天下のYouTube様のご意向に逆らうことになっちゃうんですね。それは嫌ですね。というかYouTubeってよくわからない事情で動画やチャンネルが突然消えたりするので、あまり深入りしたくない、触らぬ神に祟りなしです。(オンラインで字幕を編集できる機能はすごいと思いますが…。)ということで、題材としての動画ファイルは他のサイトで探すことにします。
2. Audacityで .wav 出力
何もないところからの文字起こしは途方もなく時間がかかりますけど、近頃は音声認識エンジンという便利なソフトがあって、そこそこの精度で音声からテキストを出力してくれます。モジオコシャー(文字起こしをする人)は動画なり音声なりを再生しながら、そのテキストを修正すればいいのです。で、エンジンが必要とする音声データの形式が決まっているので、Audacityからその形式で書き出します。
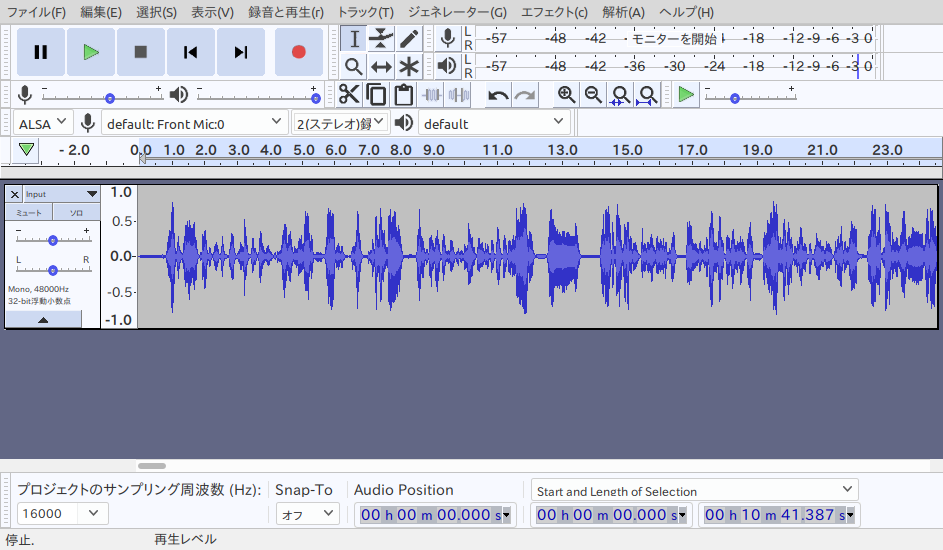
3. Audacityでセグメンテーション
2で作った音声データを解析して沈黙部分を検出します。一連の話の中で、息継ぎで沈黙になる箇所が発生します。こういう部分がたいてい文章にした時の句読点の位置にふさわしいので、パラメータを指定して沈黙の箇所にラベルを付けます。ラベルの位置データはテキストファイルに書き出すことができます。
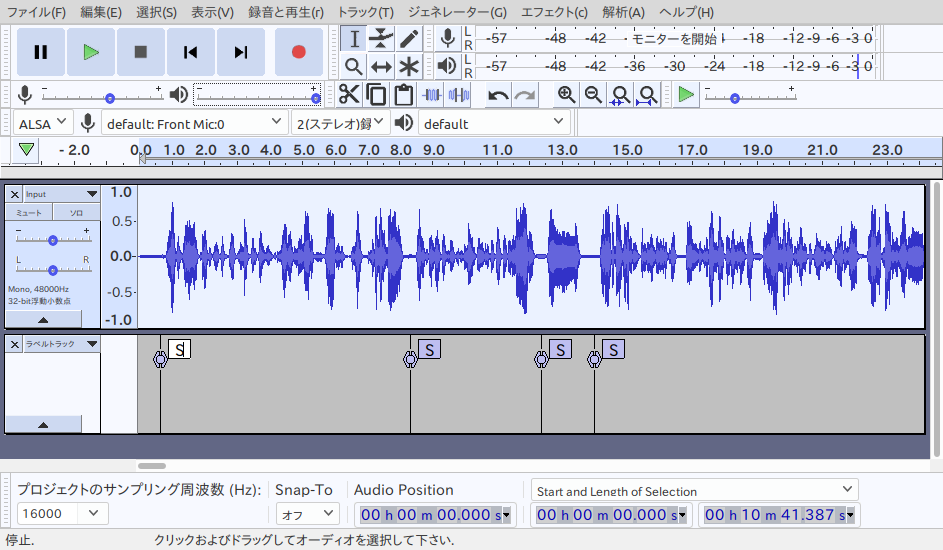
ラベルトラックのデータは以下のようなテキストファイルです:
0.690000 0.690000 S
8.360000 8.360000 S
12.410000 12.410000 S
14.040000 14.040000 S
48.930000 48.930000 S
139.470000 139.470000 S
148.060000 148.060000 S
197.890000 197.890000 S
235.860000 235.860000 S
4. 小分けファイルの作成
Pythonのオーディオ関連のライブラリ pydub から AudioSegment をインポートしておきます。ラベルトラックの数字(秒)に基づいて小分けファイルを作ります。
import datetime
from pydub import AudioSegment
# 小分けファイルを作るための開始位置と終了位置のデータを返す
def SegBySilence():
with open(AudacityLabel, "r") as f:
Silence = f.readlines()
i = 0
segmentation = []
for i in range(len(Silence)):
try:
j = i + 1
StartSec = float(Silence[i].split("\t")[0])
EndSec = float(Silence[j].split("\t")[0])
# 長すぎ又は短すぎを防ぐ→Audacityに戻ってラベルの修正
ClipLen = EndSec - StartSec
td = datetime.timedelta(seconds=StartSec)
if ClipLen > 10: # 10秒を超える
print("長すぎる!", td)
if ClipLen < 1:
print("短っ!", td)
Duration = ("speech", StartSec, EndSec)
segmentation.append(Duration)
except IndexError:
pass
return segmentation
# セグメンテーションデータに基づき小分けファイルを作る
def Kowake(Segments):
LoopCount = 0
forJuliusSilence = AudioSegment.silent(duration=300)
# 音声
for Seg in Segments:
# タプルの第1要素が区間のラベル
SegLabel = Seg[0]
if (SegLabel == 'speech'): # 音声区間
# 区間の開始時刻の単位を秒からミリ秒に変換
StartSec = Seg[1] * 1000
EndSec = Seg[2] * 1000
# 分割結果をwavに出力 Julius用
NewAudio = AudioSegment.from_wav(AudioFile)
NewAudio = forJuliusSilence + NewAudio[StartSec:EndSec] + forJuliusSilence
OutFile = KowakeDir + "S" + str(LoopCount).zfill(4) + '.wav'
OutVideo = KowakeDir + "V" + str(LoopCount).zfill(4) + '.mp4'
NewAudio.export(OutFile, format="wav")
# 分割結果をmp4に出力
# ffmpeg -ss [開始地点(秒)] -i [入力する動画パス] -t [切り出す秒数] [出力する動画パス]
Vstart = Seg[1]
Vend = Seg[2]
Sec = str(Vend - Vstart)
StartTime = str(Vstart)
cmd = "ffmpeg -ss " + StartTime + " -i " + VideoFile + " -t " + Sec + " " + OutVideo
os.system(cmd)
LoopCount += 1
del NewAudio
5. 音声認識エンジンでとりあえずの文字起こし文
日本語は Julius、英語は DeepSpeech を使います。どちらもサンプリング周波数16000Hz・モノラルの音声を認識します。Juliusでも英語のモデルが使えるらしいのだけど、うちの環境というか設定ではうまく動かなかった。
1クリップがなるべく10秒以下になるように小分けして音声認識エンジンにかけます。
# J か E でエンジンの種類を指定
Lang = "J"
def RunRecogEngine():
os.chdir(KowakeDir)
cmd = "ls -v S*.wav > wavlist.txt" # ls -v natural sort of (version) numbers within text
os.system(cmd)
with open("wavlist.txt", "r") as f:
Lines = f.readlines()
if Lang == "J":
cmd = "julius -C ../main.jconf -C ../am-dnn.jconf -quiet -dnnconf ../julius.dnnconf -input rawfile -filelist wavlist.txt -outfile -iwspword -rejectshort 300"
os.system(cmd)
elif Lang == "E":
#cmd = "julius -C ../ENVR-v5.4.Dnn.Bin/julius.jconf -quiet -dnnconf ../ENVR-v5.4.Dnn.Bin/dnn.jconf -input rawfile -filelist wavlist.txt -outfile -iwspword -rejectshort 300"
# Juliusに英語の音声モデルを指定してやってみたけどうまく動かなかった。
for i in Lines:
OutFile = i.split(".")[0] + ".out"
cmd = "deepspeech --model ../DeepSpeech/deepspeech-0.7.0-models.pbmm --scorer ../DeepSpeech/deepspeech-0.7.0-models.scorer --audio " + i.strip() + " > " + OutFile
os.system(cmd)
else:
exit()
# .outファイルから必要な行だけ取ってEdit.Me(編集用全文ファイル)収録。
EditMe = ""
for l in Lines:
JuliusOut = l.split(".")[0] + ".out"
with open(JuliusOut, "r") as ff:
Jout = ff.readlines()
Jrecog = Jout[0]
try:
Jrecog = Jrecog.split("sentence1: ")[1]
except IndexError:
pass
# Juliusの出力には余計な文字が含まれる
if Lang == "J":
Jrecog = Jrecog.replace(" ", "")
EditMe = EditMe + Jrecog
if not os.path.exists(EditMeFile):
with open(EditMeFile, "w") as fff:
fff.write(EditMe)
6. 小分け動画を再生しながらテキスト編集
※ 豊島区議会議員くつざわ氏のコンテンツをニコニコ動画からダウンロードして文字起こしをしています。
(同じ動画がYouTubeにもありますけど、そちらからはダウンロードしてませんよ ( ̄▽ ̄)
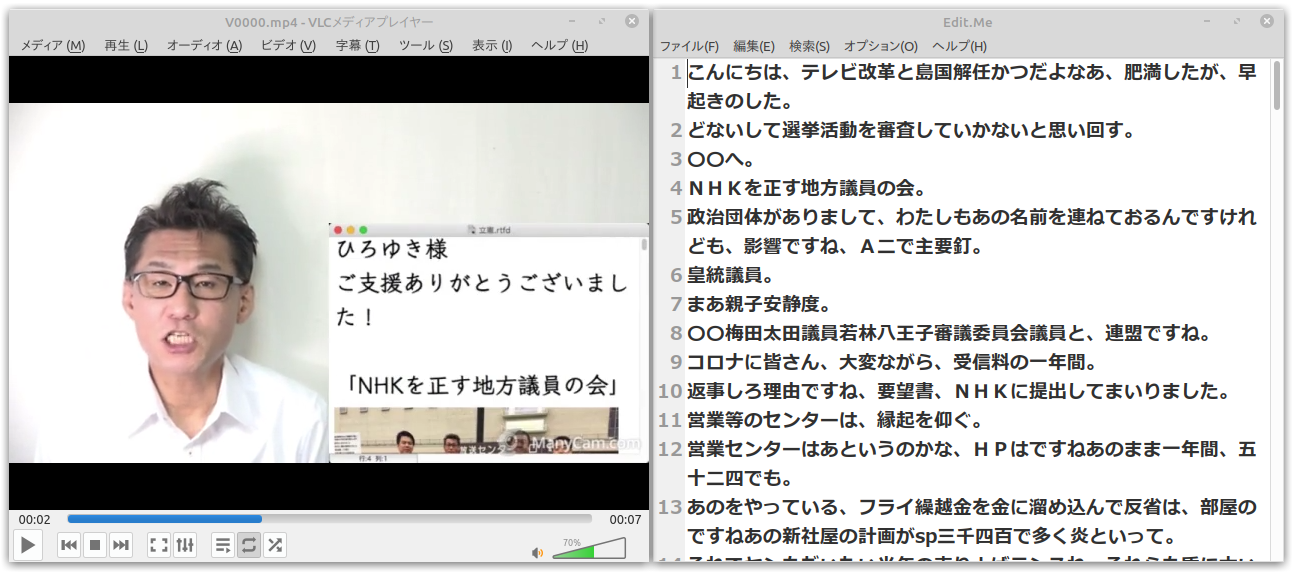
認識結果は1クリップ1行でテキストファイルに保存されています。VLCメディアプレーヤーで繰り返し再生の指定をして動画の再生をする一方で、エンジンによって生成されたテキストを修正していきます。テキストファイルのタイムスタンプが更新されたら次のクリップに進む、という仕組みになっていますが…。
この方法で問題なのは、次のクリップに進むたびにウィンドウのフォーカスがメディアプレーヤーの方に移ってしまい、文字修正のタイピングが滞ってしまうことです。文字起こしを快適に進めるためには余計な操作(キーボードから手を離してマウスに持ち替える、あるいはショートカットでテキストエディタのウィンドウにフォーカスを戻す)はしたくありません。
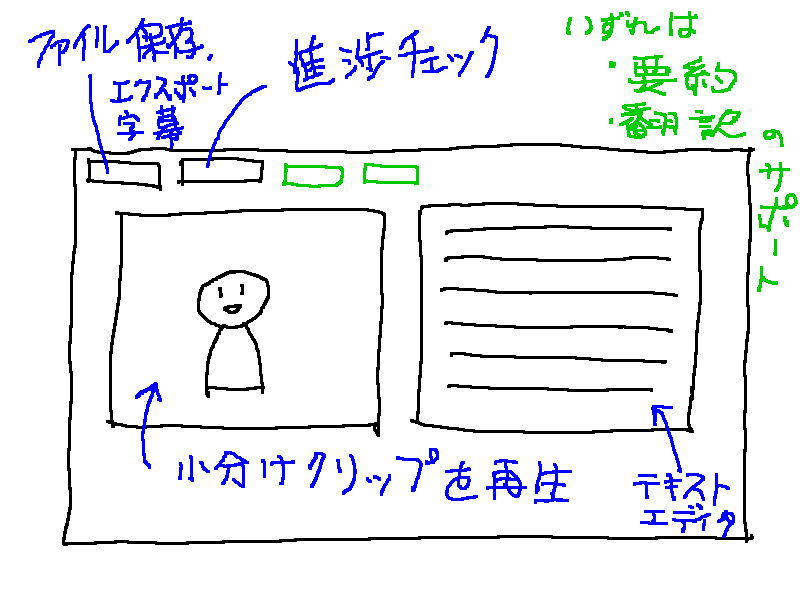
そこで、既成のメディアプレーヤーやテキストエディタを使わずに、1つのウィンドウの中で動画再生とテキスト編集ができるアプリが欲しくなったのです。
こういうアプリを作って使いたい
Python GTK+3 で何とかなりそうな気がしてるのですが、無謀でしょうか…?