The Python GTK+ 3 Tutorial【4. How to Deal With Strings】でもサンプルコードがないので説明文の翻訳と、idle (Pythonコンソール)の打ち込みで勉強します。
この章の2節はPython 2における文字列の説明なので省略します。たぶんこの先Python 2でプログラムを書くことはないだろうと思うので。
ここでは Python 3.x GTK+で文字列がどのように表現されるかを説明します。また、文字列を扱う際に発生する一般的なエラーについても説明します。
4.1. 定義
概念的には、文字列は’A’、‘B’、‘C’、‘E’などの文字のリストです。文字は抽象的な表現であり、その意味は使用される言語と文脈に依存します。Unicode標準は、文字がコードポイントによってどのように表されるかを説明しています。例えば、上記の文字はそれぞれコードポイント U+0041、U+0042、U+0043、および U+00C9 で表現されています。基本的にコードポイントは0~0x10FFFFの範囲の数字です。
前述したように、文字列をコードポイントのリストとして表現することは抽象的です。この抽象表現をバイト列に変換するには、Unicode文字列をエンコードしなければなりません。エンコードの最も単純な形式はASCIIで、以下のように実行されます。
-
コードポイントが<128の場合、各バイトはコードポイントの値と同じになります。
-
コードポイントが128以上の場合、このエンコーディングではUnicode文字列を表現できません。(Python はこの場合、UnicodeEncodeError 例外を発生させます)。
ASCII エンコーディングは適用するのは簡単ですが、128種類の文字しかエンコードできません。この問題を解決するために最も一般的に使用されているエンコーディングの一つが UTF-8 です (これはあらゆる Unicode コードポイントを扱うことができます)。UTFは “Unicode Transformation Format"の略で、“8"はエンコーディングに8ビットの数字が使用されることを意味します。
4.3. Python 3
4.3.1. Python 3.x の Unicode 対応
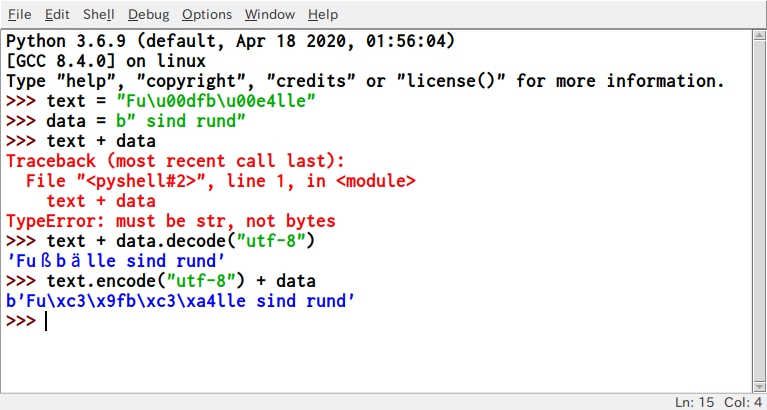
Python 3.0 以降、すべての文字列は str 型のインスタンスに Unicode として格納されます。一方、エンコードされた文字列は bytes 型のインスタンスの形でバイナリデータとして表現されます。概念的には、str はテキストを指し、byte はデータを指します。str からバイトへの移動には str.encode() を使用し、バイトから str への移動には bytes.decode() を使用します。
また、TypeErrorが発生するため、Unicode文字列とエンコードされた文字列を混在させることはできなくなりました。
4.3.2. GTK+ における Unicode
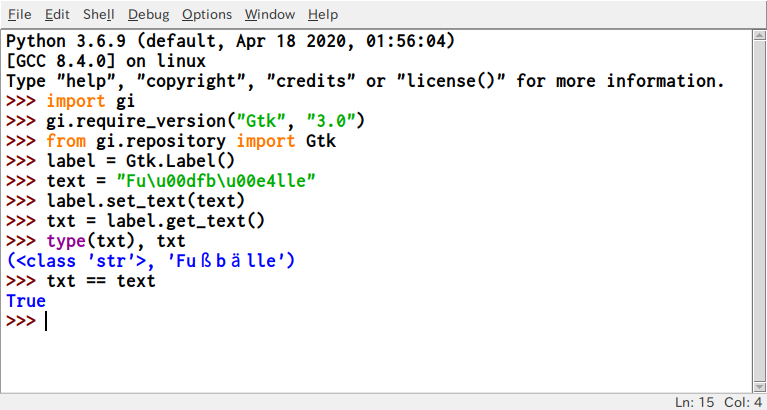
PyGObject は文字列をメソッドに渡したり、メソッドが文字列を返したりする場合、自動的に UTF-8 へのエンコード/デコードを行います。その結果として、Python 3.xとの整合性が大幅に向上しています。文字列やテキストは常に str のみのインスタンスとして表現されます。
4.4. 参考資料
-
What’s new in Python 3.0 テキストとデータを明確に区別する新しい概念を説明しています。
-
Unicode HOWTO Python 2.x の Unicode サポートについて議論し、Unicode で作業するときによく遭遇する様々な問題について説明しています。
-
Unicode HOWTO for Python 3.x Python 3.x での Unicode サポートについて語っています。
-
UTF-8 encoding table and Unicode characters Unicode コードポイントのリストと、それぞれの UTF-8 エンコーディングが含まれています。


